发布日期:2024-09-25 13:13 点击次数:118
本文实例诠释了Java爬取豆瓣电影数据的次序。共享给群众供群众参考柚子猫 足交,具体如下:
所用到的技能有Jsoup,HttpClient。
Jsoup
jsoup 是一款Java 的HTML通晓器,可平直通晓某个URL地址、HTML文本推行。它提供了一套特别省力的API,可通过DOM,CSS以及雷同于jQuery的操作次序来取出和操作数据。
HttpClient
HTTP 条约可能是刻下 Internet 上使用得最多、最蹙迫的条约了,越来越多的 Java 应用门径需要平直通过 HTTP 条约来拜谒汇注资源。诚然在 JDK 的 java net包中照旧提供了拜谒 HTTP 条约的基本功能,然而对于大部分应用门径来说,JDK 库自己提供的功能还不够丰富和天真。HttpClient 是 Apache Jakarta Common 下的子阵势,用来提供高效的、最新的、功能丰富的救助 HTTP 条约的客户端编程用具包,况且它救助 HTTP 条约最新的版块和忽视。
爬取豆瓣电影数据
豆瓣电影网址。
通达浏览器f12,地址栏中输入该地址拜谒,不错看到肯求反馈的页面,对应不错找到电影数据的肯求地址,数据肯求地址
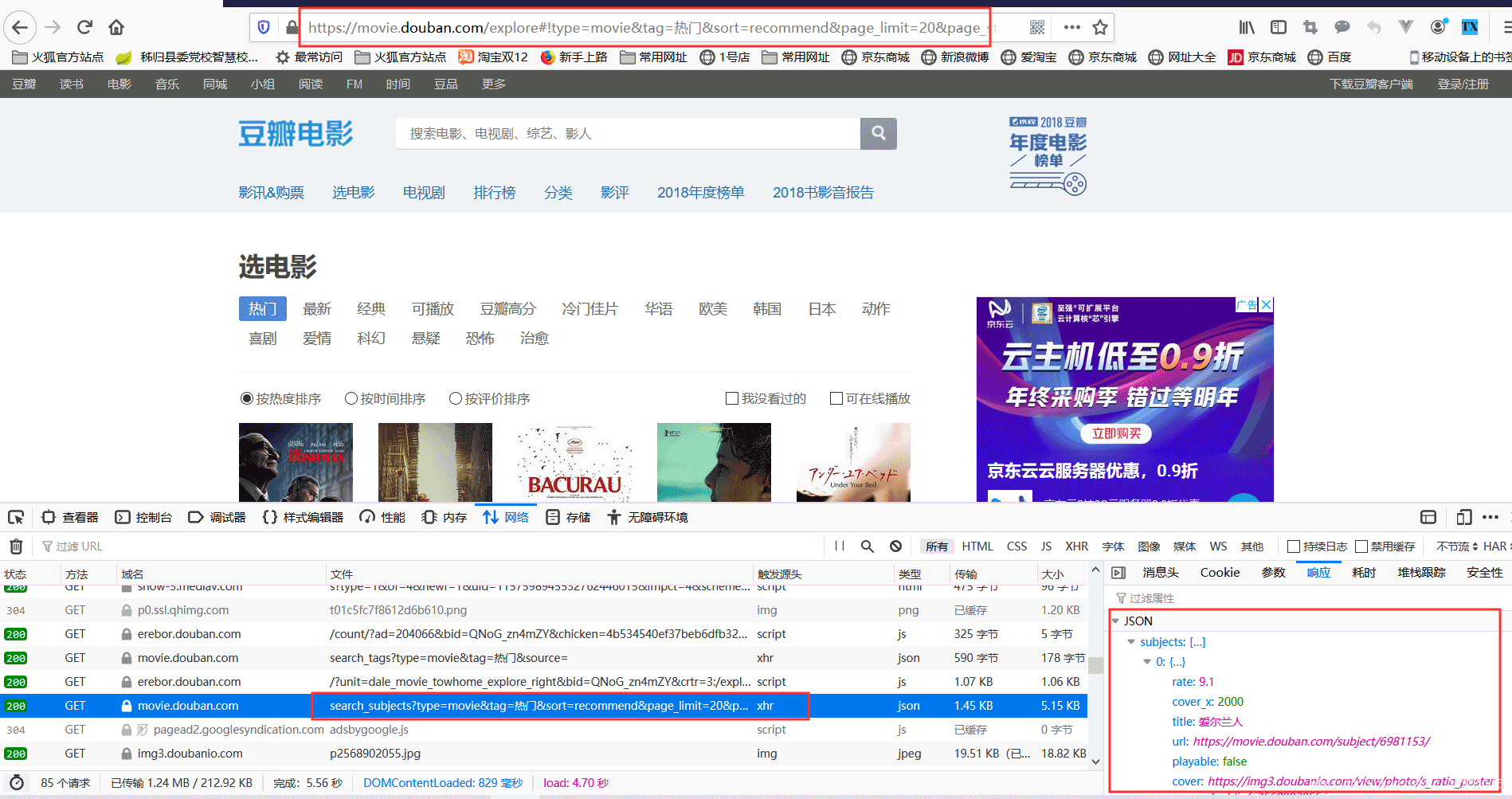
不错看到数据肯求地址反馈过来的是一个JSON方式的数据,之后咱们看到肯求地址上的参数type=movie&tag=热点&sort=recommend&page_limit=20&page_start=0。其中type是电影tag是标签,sort是按照热点进行排序的,page_limit是每页20条数据,page_start是从第几条数据启动查询(下标从0启动)。然而这不是咱们思要的,咱们需要去找豆瓣电影数据的总进口地址是底下这个
创建SpringBoot阵势爬取数据
把爬取到的数据保存到数据库中,电影图片保存在腹地磁盘中,这里捏久层用的是JPA,是以需要引入对应的依赖。pom.xml中依赖代码如下。
阵势目次结构如下。
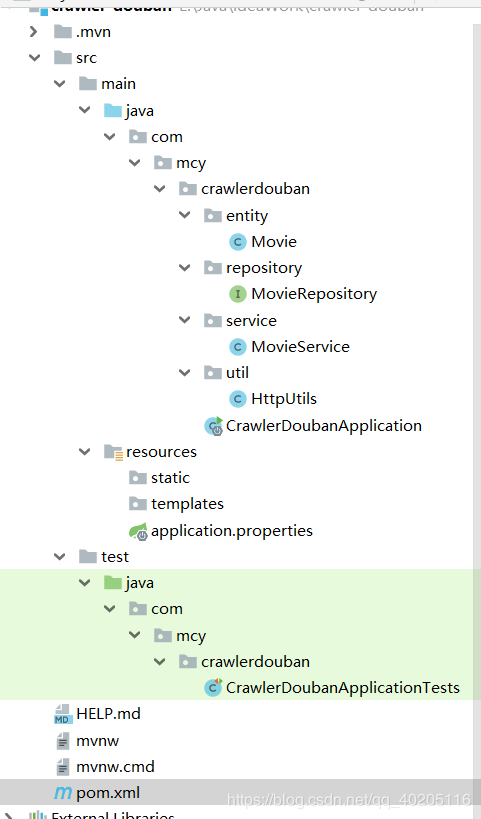
当先咱们在entity包中开导实体对象,字段为豆瓣电影的基本信息(有些信息是细目页面的信息)。
Movie实体类。
在src/main/resources下找到application.properties文献,在该设置文献中设置数据库流畅信息,需要在数据库中新建一个名为douban的数据库。
创建MovieRepository数据拜谒层接口柚子猫 足交
创建MovieService类,里边有一个保存数据的次序。
创建一个HttpUtils获取网页数据和保存图片的用具类。
创建聚合池和设置聚合池信息。
把柄肯求地址获取反馈信息次序,获取告捷后复返反馈信息。
把柄流畅下载图片保存到腹地次序。
HttpUtils用具类一齐代码。
在项观点test类中编写代码获取数据保存到数据库中。
先通过@Resource注解将MovieService类对应的终了类注入进来。
诞生肯求地址https://movie.douban.com/j/search_subjects
之后在界说两个Map,用于存储肯求头和肯求参数信息。
网页肯求头。
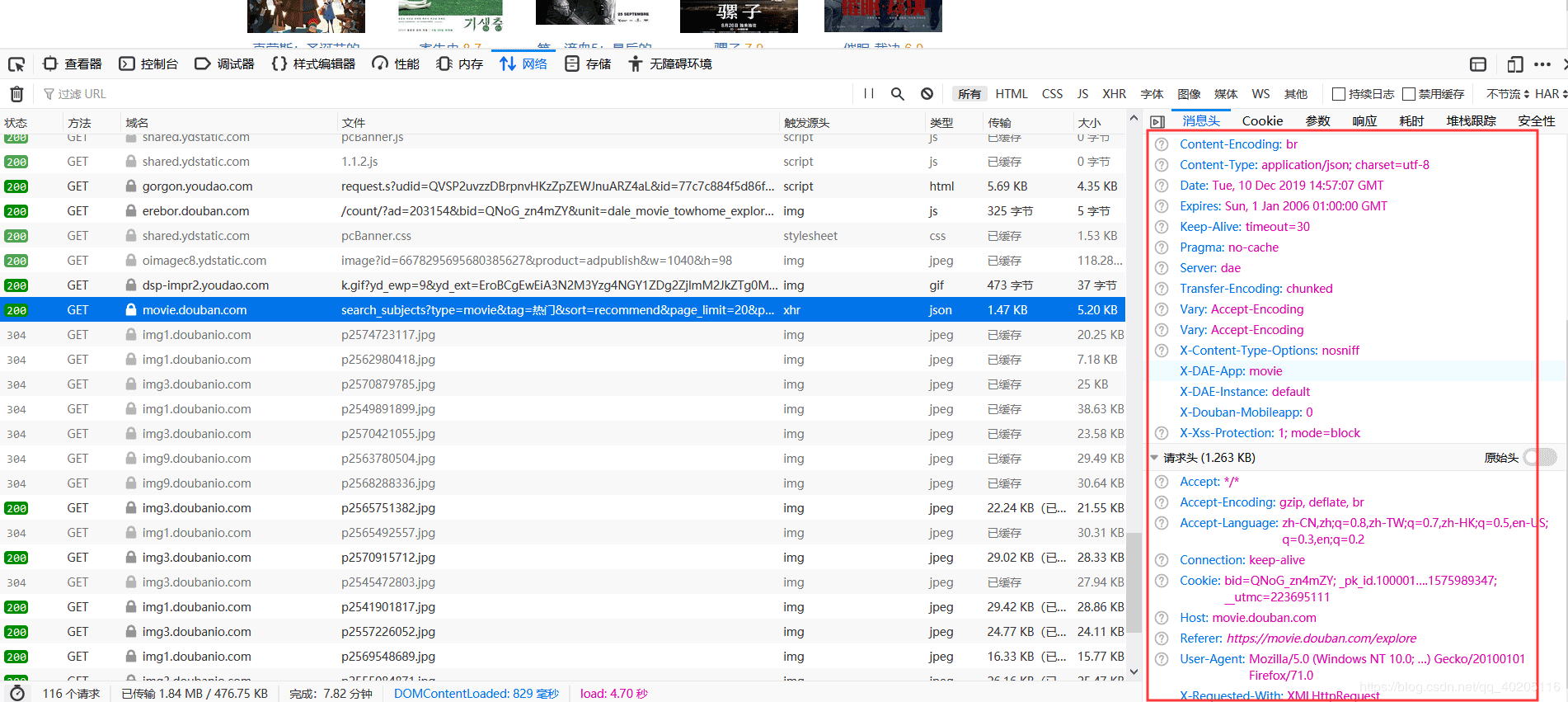
肯求参数,type=movie&tag=热点&sort=recommend&page_limit=20&page_start=0
诞生肯求参数和肯求头代码如下。
通过HttpUtils类doGetHtml次序获取该肯求反馈的数据。
超碰在线肯求反馈数据方式。
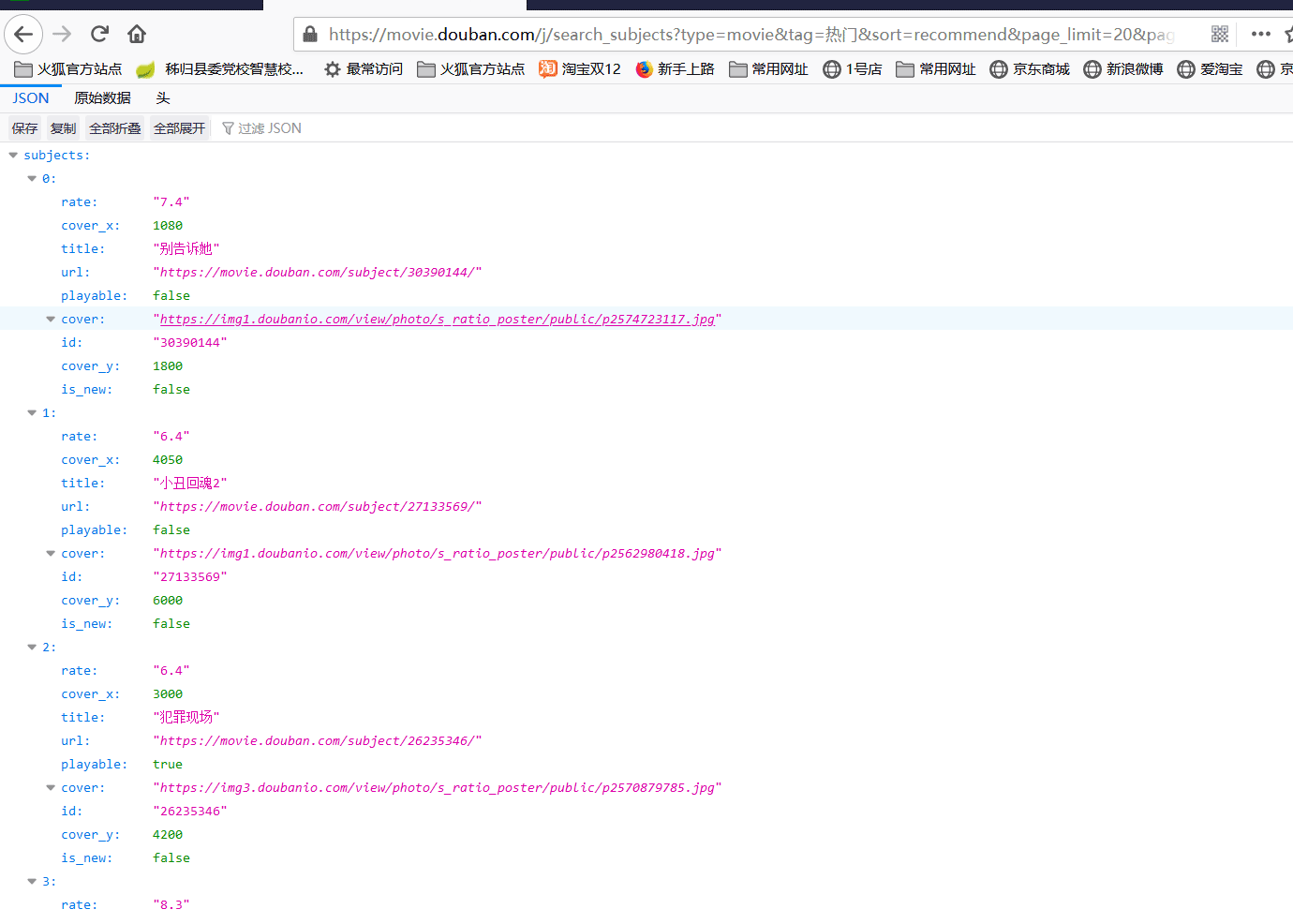
不错看出是一个json方式的数据,咱们不错通过阿里巴巴的Fastjson一个json通晓库,把它通晓成为一个List方式数据。Fastjson基本用法
因为每页查询是是20条数据,咱们用一个for轮回遍历一下这一页的数据。不错取得电影的标题,评分,图片流畅和细目页面的流畅,上头JSON数据中的cover属性值为图片的地址。通过图片的流畅咱们不错调用HttpUtils类的doGetImage次序把图片保存到腹地磁盘。
上头肯求的数据只可获取到标题,评分和图片,关连词咱们还有获取导演,主演,和电影时长。这些信息咱们点开上头肯求到的json数据的url属性值,会通达细目页面,细目页面中有导演,主演,和电影时长信息。
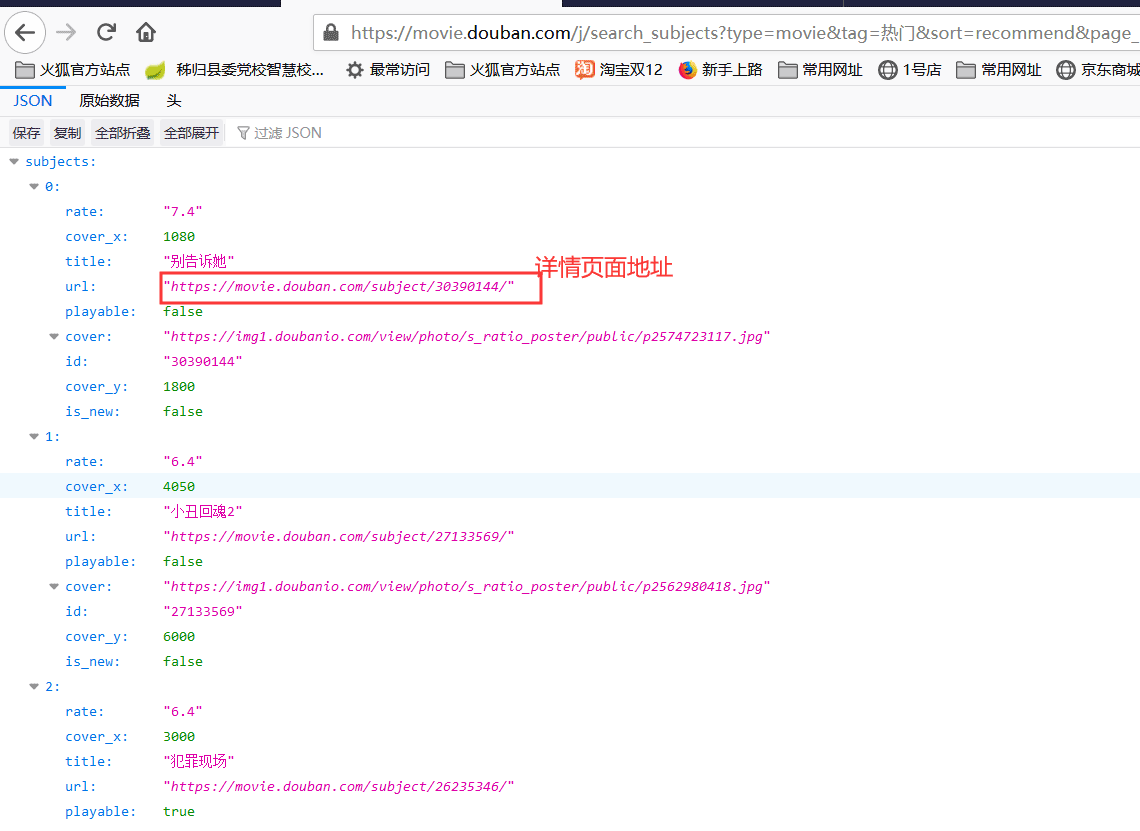
通达的细目页面,咱们不错看到导演,主演和电影时长等信息。
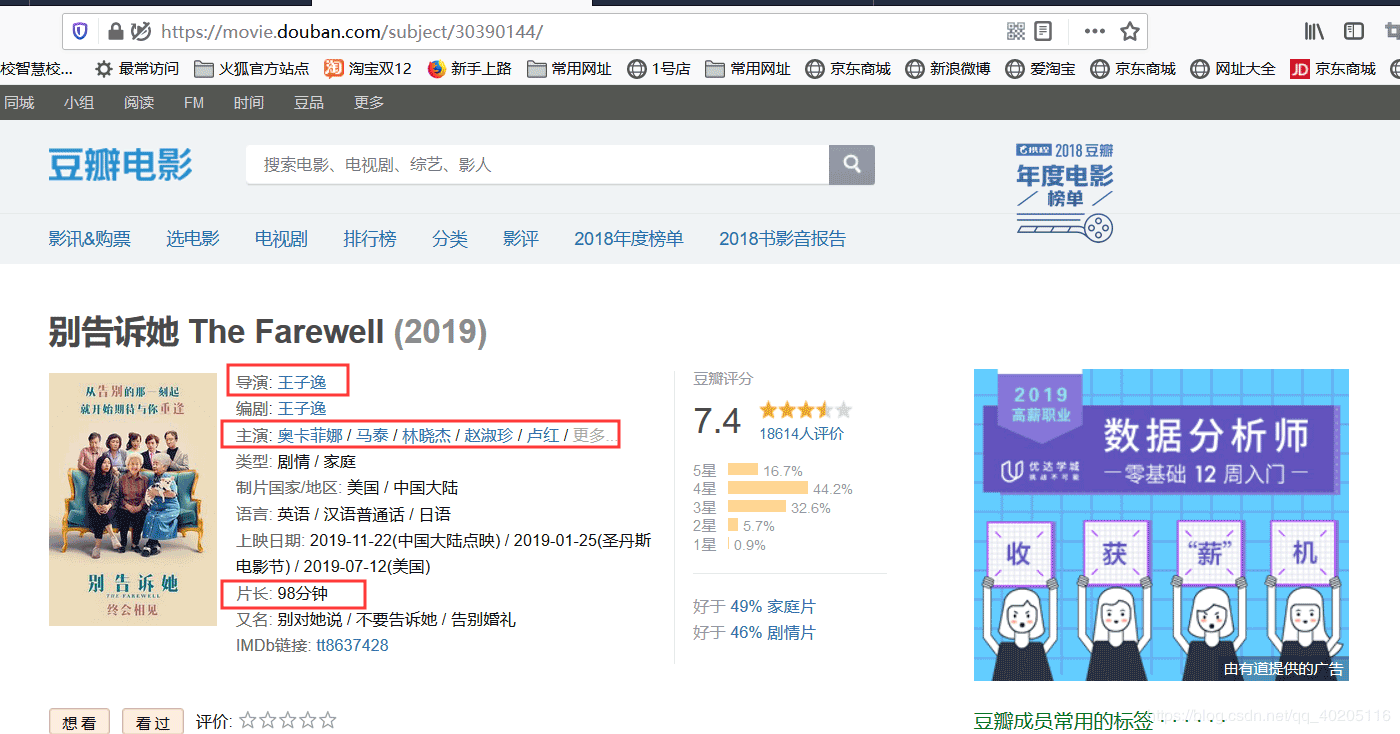
咱们查询细目页面的源代码,不错看到导演,主演,电影时长等信息的位置。
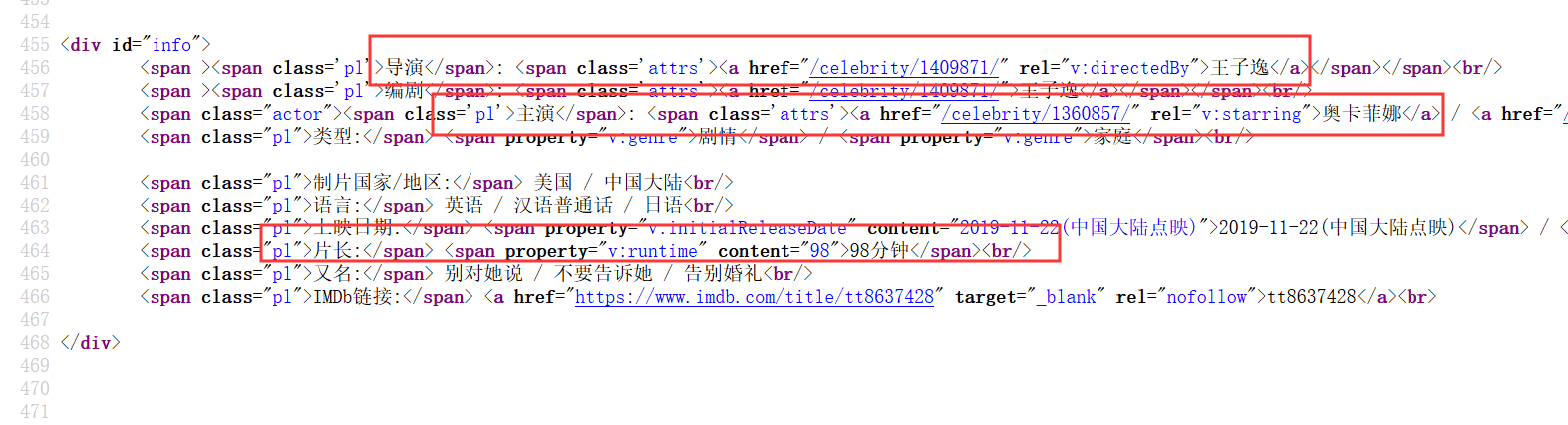
咱们在通过HttpUtils类doGetHtml次序获取细目页面的数据,诓骗Jsoup进行通晓,Jsoup是一个不错让java代码通晓HTML代码的一个用具,不错参考一下Jsoup官网文档,找到主演,导演和电影时长信息。到这里咱们需要的一齐信息王人获取到了,终末把数据保存起来。
测试类一齐代码如下。
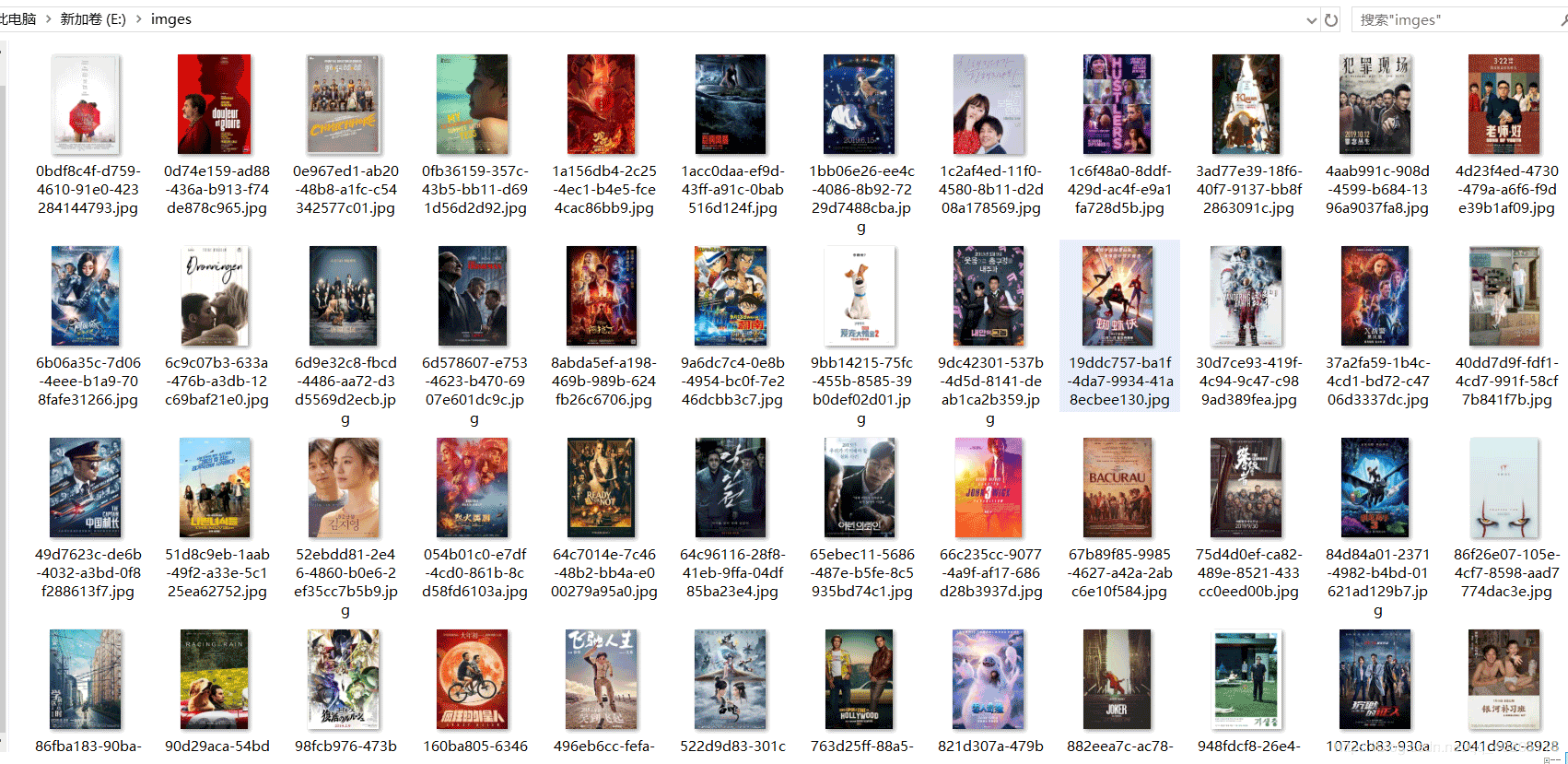
终末咱们在mysql数据库中新建一个名为douban的数据库,启动阵势,JPA会自动在数据库中新建一张movie表,存放获取到的电影数据。在腹地磁盘也会保存电影图片,如图。
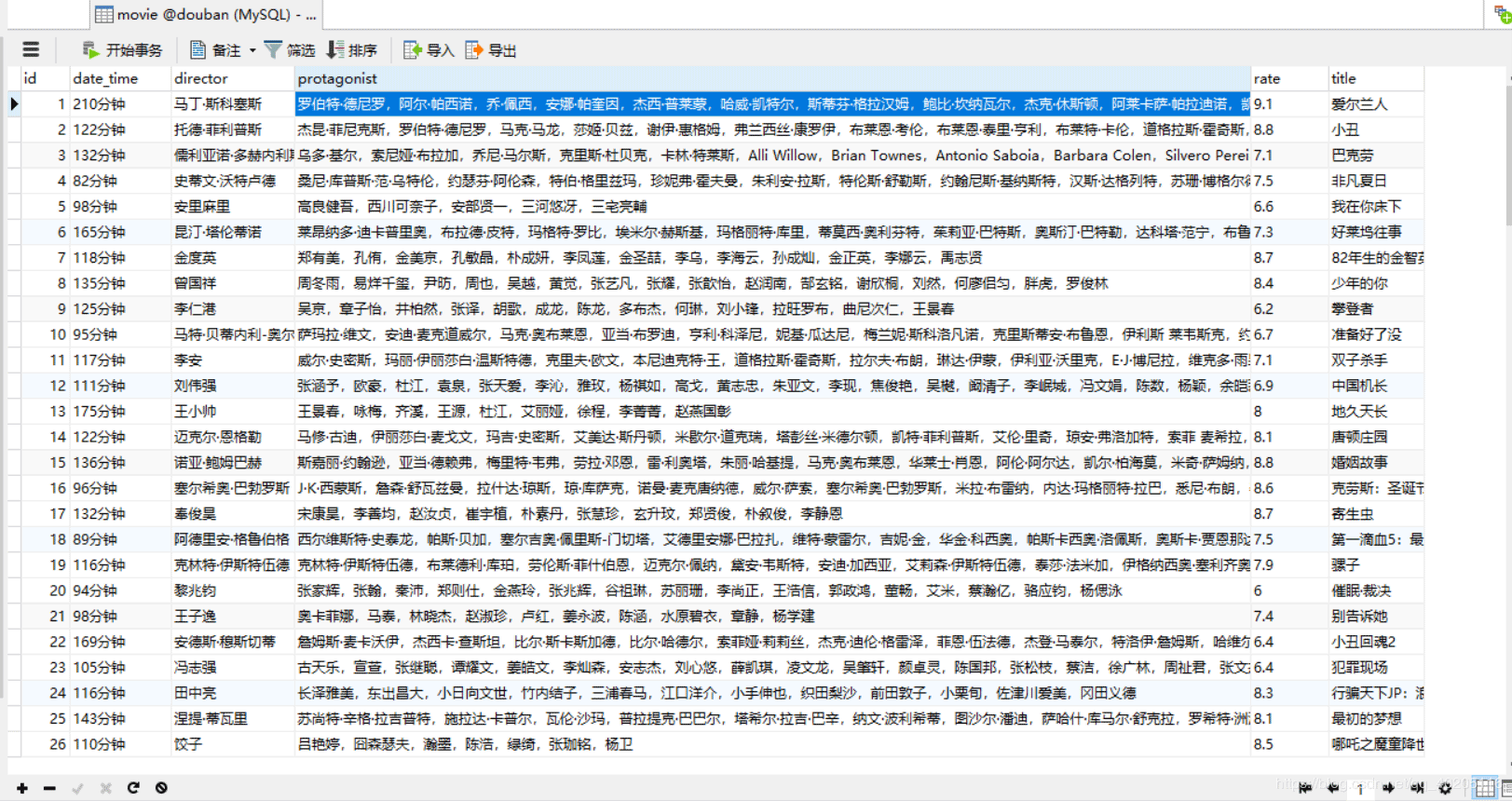
电影图片,保存的位置和HttpUtils的doGetImage次序中诞生的保存地址相同。
终末放高下载地址https://github.com/machaoyin/crawler-douban
有什么问题迎接下方留言相通。
更多对于java关连推行感意思意思的读者可搜检本站专题:《Java汇注编程妙技追思》、《Java Socket编程妙技追思》、《Java文献与目次操作妙技汇总》、《Java数据结构与算法教程》、《Java操作DOM节点妙技追思》和《Java缓存操作妙技汇总》
但愿本文所述对群众java门径缱绻有所匡助柚子猫 足交。
您可能感意思意思的著述: Java爬取网站源代码和流畅代码实例 Java 爬虫何如爬取需要登录的网站 java通过Jsoup爬取网页进程详解 Java终了爬取百度图片的次序分析 Java爬虫终了爬取京东上的手机搜索页面 HttpCliient+Jsoup java终了爬取知乎用户基本信息 java爬取豆瓣电影示例通晓